

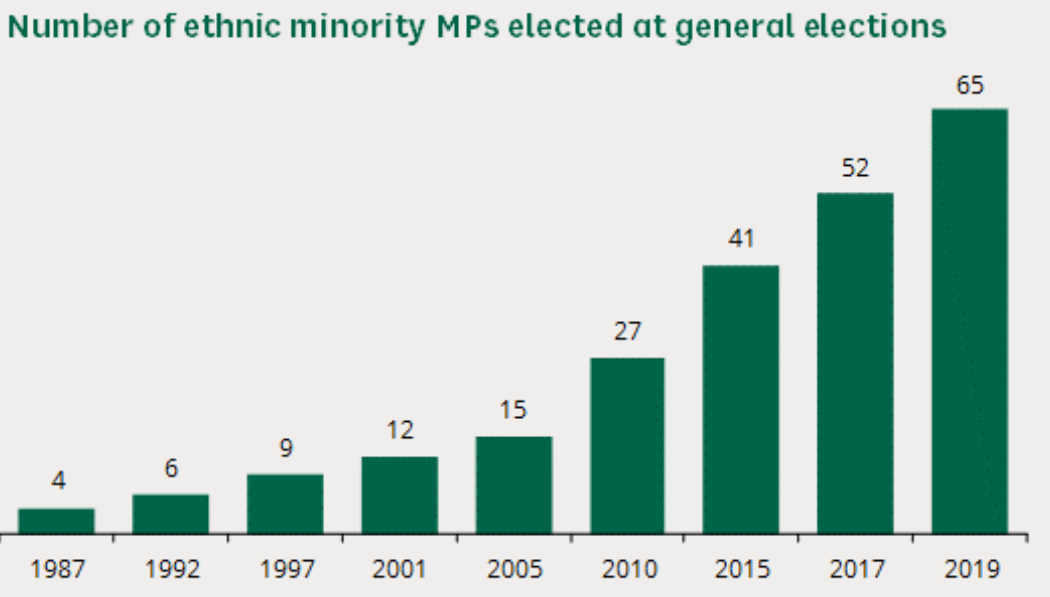
Will 2029 see the emergence of successful faith-based political parties in Westminster
Using the Origins Classification to examine the influence of Ethnicity of the results of the UK 2024 General Election.
Infer Diversity
OriginsInfo is a consumer insights consultancy and analytics tool enabling applications and businesses to acquire valuable customer insights purely from a first or last name.
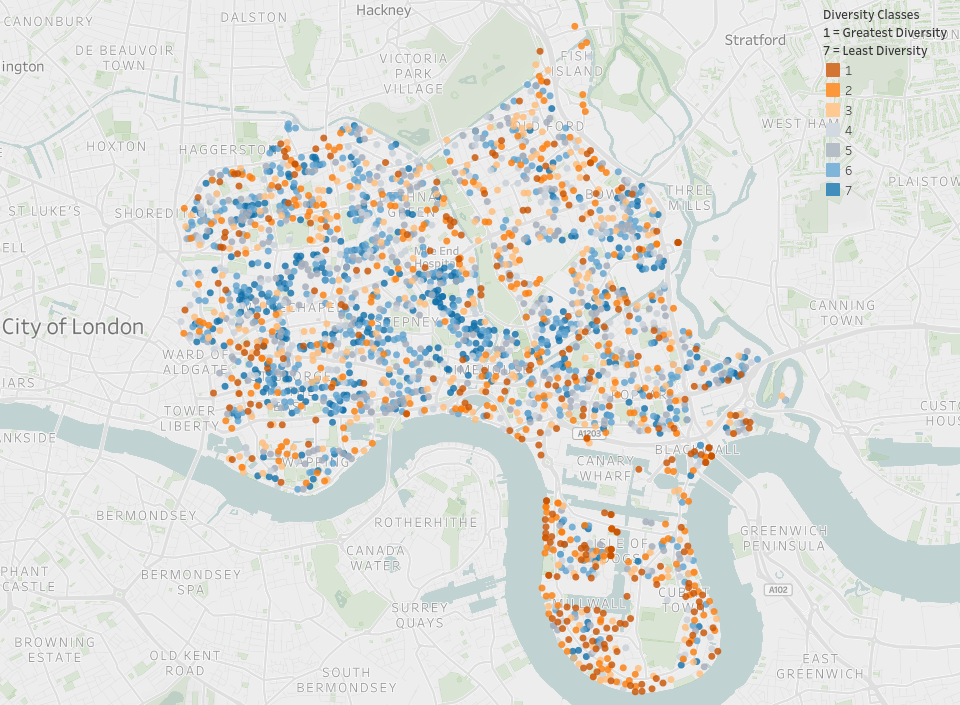
Using Onomastics to drive diversity insights
First and lastnames carry a compelling cultural fingerprint, powerful enough to infer cultural heiritage.
In most cases a first and last name combination is non identifiable. This allows for personal and last names to be collected and analysizd in a compliant way.
With cultural heritage as a dimension we can gain further data insighs.
Empowering social justice by helping to identify marginalized social groups or facilitate social support program to identify the deprived.
Discover how the power of Onomastics can add diversity dimentions to your data sets.
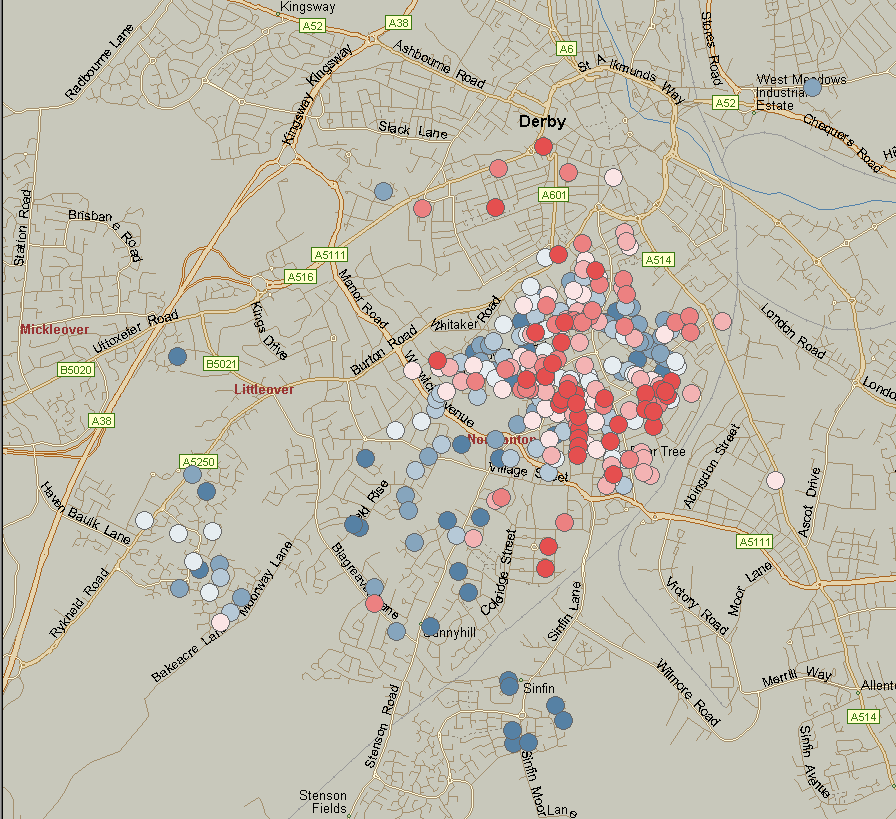
NHS England queues in Algate East spiked to levels where patient analytics were require to assertain the high waiting times.
Using the power of Onomatics, Originsinfo was able to provide ethnical analysis on patient records to assertain that members of a certain community where over represented in Accident and Emergency. Following a targeted ethnicity campaign, waiting times where reduced by encourage local GP visits instead.
Optimize deployment of policing resources.
Ethnical analysis on crime statistics on a postal areas level allowed for more strategic of neighborhood policing resources in addition to better understanding crime hotspots.
Explore our collection of publications and case-studies on Diversity insights.
Using the Origins Classification to examine the influence of Ethnicity of the results of the UK 2024 General Election.

This paper illustrates how the Origins software can provide insights into diversity among employees; in this case the list of employees of The National Theatre
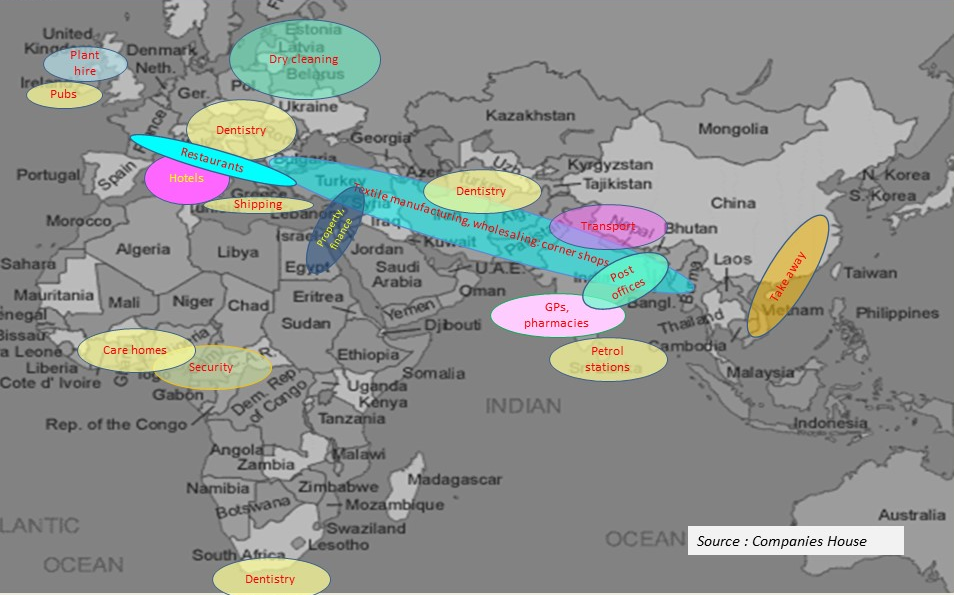
An evidence base for tackling social cohesion
Downstairs two plumbers are busy replacing my central heating boiler. Their names are Barry and Jerry. For me it is quite an unusual experience to deal with suppliers of English heritage.
Step 1: Download
Download either our Desktop application, SDK or use secure cloud APIs
Step 2: Import local data
Import local data files (e.g CSV.) containing first and last name columns
Step 3: Secure and compliant processing of local data.
Allow our software to analyise your local-data, on your terms. Data does not have to be uploaded to the cloud for processing.
Ready!

Process local files
Workflow integration using CLI scripts
Embedding and full workflow integrations
The Origins classification is built from a global file containing the personal and family names of some 527,000,000 adults from around the world. In addition we have access to personal and family name frequencies covering another 529,000,000 adults. These billion adults are resident in 18 different countries.
Using this information we have been able to establish the likely Origins code for some 2,000,000 different family names and some 700,000 personal names.
Origins is used to profile customers and customer segments, citizens and service users, employees and even suppliers. By profiling customers you can identify which groups are under or over-represented on your customer file. You can find out which groups prefer to use which products, channels and outlets, which ones you are good or poor at retaining and which are responsive to which types of promotion or reward.
Origins is used to code customers. By coding customers you can target campaigns to improve awareness and take up of public services by members of specific minority groups. You can also target products, such as cosmetics, media channels and travel, at audiences for whom they have been especially developed.
Origins is used to classify postcodes. Using a table which identifies the dominant Origins type in each postcode you can identify and map the locations in which individual communities have established themselves right down to street level.
Provided you files free of data capture errors, you should be able to code 99.5% of your customer records by Origins type. The residue are either names which the system does not recognise, because they are rare, or ones which the system can not allocate to any particular Origins type.
The level of accuracy varies from one Origins type to another. Origins achieves accuracy rates in excess of 90% in identifying South Asians and Muslims, and 70% in identifying Black Africans, Greeks, Armenians and people from East and South East Europe. It achieves accuracy rates of 50% with Hispanics. Lower accuracy rates are achieved with people of Nordic or French origin, with Jews and Black Caribbeans.
As would be expected the system is more accurate when coding names to a general categories, such as South Asians or Greeks or Greek Cypriots, than to specific sub-categories, such as Sri Lankans or Greek Cypriots.
Origins can be used to identify persons whose names come from more than one tradition – for example a person with an English personal name and a Finnish family name.
The confidence score given to each name combination can also be used to select or deselect people who are most likely to be of mixed ancestry. Restricting a communication to names with high confidence scores is an effective way of avoiding communicating with individuals who are least likely to belong to the selected target group.
When Origins is used to profile customer, citizen or employee files it is possible to compare the distribution of records by Origins on your file with the distribution of the population by Origins in the geographical region which you serve or from which your employees are drawn.
For example you can specify as your base comparison any administrative region, local authority district, postcode area, police, education or health area in Great Britain. The distribution of the population by Origins is also available for regions of the USA and other European countries.
Although Origins is a single application, it has facilities whereby it can be optimised for specific international markets. These international versions code certain names differently in different markets. For example a ‘Roger’, which would be coded as ‘English’ in Britain, would be coded ‘French’ in France. Non GB versions of Origins also allow the mix of names by Origins type to be compared with the Origins mix for the specific market in which the analysis is undertaken.
The product is particularly attractive to international organisations who need a consistent basis for analysing diversity in each of the national markets in which they operate.
Output can be configured for local languages and needs. For example the way in which the Origins categories are best grouped will be different in Australia from in the Netherlands. The system provides complete flexibility over classing.
Origins types and groups can be appended to customer records using Origins software applications. These applications are licensed to clients by our global partners. A PC version is downloadable from the internet and accesses reference files which are updated on a regular basis as names from more countries are introduced to the system.
The licence fee depends upon the version of the application licensed. A standard version of the application is designed to code names appearing on British or Irish customer lists. An enhanced version also appends gender and an estimate of life-stage. Versions of Origins can also be licensed optimised for different overseas national markets. Origins can also be accessed using an API server; or files can be sent directly to Origins Info for coding.
Have questions? Feel free to contact us.
contact@originsinfo.com